窦 颖,孙晓荣 *,刘翠玲,位丽娜,胡玉君
(北京工商大学计算机与信息工程学院,北京 100048)
摘 要:研究提出基于支持向量机(support vector machine,SVM)算法结合红外衰减全反射光谱对不同种类的面粉进行快速分类。实验随机采集富强粉、精制雪花粉、麦芯粉及面包粉4 种共139 份常见面粉红外衰减全反射光谱,运用马氏距离筛选异常样本,并建立SVM模型对待测样本进行预测。实验采用二叉树SVM模型识别面粉种类,并通过网格法优化核函数参数,结果显示:富强粉、精制雪花粉、麦芯粉及面包粉的识别准确率分别为100%、100%、75%和85.71%,模型平均识别准确率为90.177 5%。结果表明,利用红外光谱结合SVM算法快速识别面粉种类是准确可行的。
关键词:面粉;红外衰减全反射;马氏距离;支持向量机Abstract: In the present study, we put forward an algorithm based on support vector machine (SVM) for fast identifi cation of different types of fl our by attenuated total refl ectance-Fourier transform infrared spectroscopy (ATR-FTIR). ATR-FTIR spectra of 139 samples of four common types including strong fl our, wheat core fl our, refi ned snowfl ake fl our and bread fl our, were collected randomly. The outlier samples were eliminated based on Mahalanobis distance and an SVM model was established to predict samples. The binary tree SVM model was used to identify the types of fl our, and the parameters of the kernel function were optimized by using the grid method .The results showed that the recognition accuracy reached 100%,100%, 75% and 85.71% for strong flour, refined snowflake flour, wheat core flour and bread flour, respectively, and the average recognition accuracy of the model was 90.177 5%. All the above results indicate that it is feasible to use ATR-FTIR with SVM algorithm for quick and accurate identifi cation of different types of fl our.
面粉富含蛋白质、维生素以及人体所需的酶和微量元素等营养物质,加之其制成的食品种类繁多,一直是国民日常生活中必不可少的主食之一。随着人们日常饮食的丰富,市场为满足消费者的需求,也相继推出许多不同用途以及品质的面粉商品。其中最为常见的有富强粉、麦芯粉、精制雪花粉,以及面包粉等种类,价格参差不齐,甚至是相差几倍。由于消费者仅从面粉的外观很难辨别其种类,一些不法商贩和小作坊便将低价的面粉鱼目混珠充当高价面粉贩卖,以此谋得高额的差价,侵害消费者利益,类似新闻在全国各地均有报道。虽然监管部门积极打击此类现象,但是需要先对面粉成分进行检测再通过成分含量来鉴别其类别,方法繁琐,不适合随机抽查,快速鉴别。
红外光谱波长范围位于2.5~25 μm之间,在物质鉴别方面发展成熟,且有简便快捷、分析成本低、样本用量少、可反复实验等优点,在食品、药物、珠宝、文物、石油、土壤等物质的鉴别分析中都有良好的应用 [1-6]。衰减全反射测量附件 [7]在20世纪80年代初开始应用到红外光谱仪,极大简化了一些样品的测试操作,并且不存在干涉条纹,特征谱带清晰,已被广泛应用于各个领域的定量和定性分析 [8-10]。
支持向量机(support vector machine,SVM)是一种有监督的模式识别方法,在解决小样本、非线性及高维模式识别中表现出许多特有的优势。它的基本思想是将线性不可分的输入数据经核函数映射到一个更高维的特征空间中,通过求解一个线性约束的二次规划问题,找到一个能将输入数据线性分割的最大间隔分类面 [11-13]。SVM自20世纪90年代提出之后,在模式识别、通信、信号处理以及控制等方面都得到了较为广泛的应用 [14-16]。在食品领域 [17],谈爱玲等 [18]运用改进的SVM法鉴别普通植物源与中草药植物源蜂蜜,正确率达96.67%。张建华等 [19]采用最优二叉树SVM对蜜柚叶部病害进行识别等。
因此,在此研究基础上提出基于面粉红外衰减全反射光谱,并通过主成分分析与马氏距离剔除异常样本,结合SVM算法快速鉴别富强粉、精制雪花粉、麦芯粉和面包粉4 种类别。
1.1 材料
实验随机采集的面粉样本均来自古船面粉厂不同批次、不同种类的产品,其中包括富强粉(37 份)、麦芯粉(41 份)、精制雪花粉(32 份)以及面包粉(29 份)共计139 份样本,并进行面粉红外光谱的采集。
1.2 仪器与设备
VERTEX 70傅里叶红外光谱仪、衰减全反射附件德国Bruker公司。
1.3 方法
1.3.1 马氏距离剔除异常样本
马氏距离表示数据的协方差距离,是一种有效地计算未知样本相似度的方法 [20]。在实际应用中总体样本数应大于样本的维数,所以需对样本集进行主成分分析。提取k个主成分后,马氏距离剔除异常样本具体算法为:
按式(1)计算样本集的平均光谱:
式中:A为光谱矩阵;j为波数;n为样品数;Ā为平均光谱。
对样本集进行均值中心化处理以扩大样本间差异:
计算马氏矩阵:

式中:M为K×K维矩阵。
计算样本集各个样本到平均光谱的马氏距离:
根据n个样本到平均光谱的马氏距离,设置阈值剔除异常样本。
1.3.2 SVM原理
SVM的分类原理是在n维空间里,构造一个超平面来划分两类样本数据,要求超平面距离两类样本界限的距离最大。为求得两类样本到分类面的距离,在其两侧分别构造一个平行于分类面的超平面,在这两个超平面上的样本就是支持向量。
给定训练集{x i,y i},i=1,2,……,n,y iΣ{-1,1}表示样本x i的类别,x iΣR D(x i有D个特征)。根据训练样本的信息,建立超平面:
式中:w为超平面的法向量。要求超平面对所有样本正确分类,则样本必须满足约束条件:
式中:ζ为松弛变量,是为解决线性不可分情况,ζ≥0。因此,满足上述条件且使得||w|| 2最小的分类面就是最优超平面。解最优超平面,即确定参数w和b的值,等价于解决最优化问题:
式中:C为惩罚参数,用来平衡松弛变量和分类边界的大小。
二次优化最终结果表示为:
式中:a i为拉格朗日乘子;k(x i,x j)为核函数。
标准的SVM只能解决二分类问题,如何有效地应用与多分类问题一直是研究的热点和难点。目前常用的多分类方法有4 种:一对多、一对一、决策导向无环图,二叉树法 [21-22]。由于二叉树法克服了一对多分类法存在不可分区域,以及训练样本不平衡造成分类准确率较低等缺点,且在处理分类问题时,历经的子类SVM个数最少,具有较高的训练和测试样本速度,所以实验选择二叉树多分类方法进行面粉种类的分类与测试。
二叉树多分类法的原理主要为首先将所有类别的样本分为两个子类,每个子类通过子分类器再继续分成两个次子类,如此循环分类,直到所有子类只包含一个类别的样本,样本的分类工作结束。面粉类别的二叉树多分类示意图如图1所示。
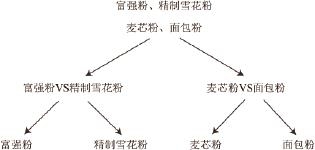
图 1 二叉树模型图
Fig.1 Binary tree model
1.4 数据分析
样本的预处理方法采用布鲁克公司OPUS光谱分析软件执行,样本的主成分分析、马氏距离的计算以及SVM模型的建立与预测均由Matlab软件执行与仿真。
2.1 数据预处理
在光谱的采集过程中会有许多干扰因素存在,并直接影响了模型的预测能力,因此在建立模型前需要对样本的光谱进行预处理,旨在降低噪声的干扰以及光谱数据无关信息的影响 [23-25]。实验采取气氛补偿及基线校正处理面粉中红外光谱采集过程中,空气里水分和二氧化碳对光谱的影响和环境中某些变化引起的光谱基线漂移等情况。最后通过均值中心化法增加面粉样本光谱之间的差异,以提高模型的稳健性与预测能力。面粉样本经气氛补偿和基线校正后的中红外光谱图和面粉样本中红外光谱均值中心化结果见图2。

图 2 经气氛补偿和基线校正后的样本光谱(AA)与经均值中心化的样本光谱(BB)
Fig.2 Spectra of samples after atmosphere compensation and baseline correction (A) and mean centralization (B)
2.2 异常样本剔除
面粉的生产、运输以及样本光谱的扫描过程中,都会有一些不可避免的因素影响面粉样本的品质,产生一些与同类别面粉差异较大的样本。基于这种情况,在建立模型前需将异常样本剔除才能使模型更稳健、准确。由于样本特征较多,实验采取主成分分析结合马氏距离剔除异常样本,通过计算提取3 个主成分,所占比重达95%以上。根据各类别样本到平均样本的马氏距离,实验将阈值设为2.5。图3为4 个类别异常样本剔除结果。

图 3 样本与平均光谱的马氏距离
Fig.3 Mahalanobis distance between samples and the average spectrum
从图3得出,异常样本共剔除17 个。其中富强粉5 个、麦芯粉5 个、面包粉2 个、精制雪花粉5 个。剩余122 个面粉样本用于SVM建模与测试。
2.3 SVM模型预测
首先将富强与精制雪花粉设为A类,麦芯粉与面包粉设为B类,使用Matlab软件建立识别两大类样本的SVM模型。共有27 份样本用于预测,其中富强粉(5 份)与精制雪花粉(7 份)共12 份,麦芯粉(8 份)与面包粉(7 份)共15 份。表1为采用不同核函数的SVM模型的分类准确率。
表 1 SVM参数设置及其分类准确率
TTaabbllee 11 PPaarraammeetteerr sseettttiinnggss aanndd ccllaassssiiffi i ccaattiioonn aaccccuurraaccyy ooff SSVVMM

核函数 参数 预测准确率/%惩罚参数 Gamma参数线性 512 无 44.444 4多项式 32 16 77.777 8 RBF 1 024 0.125 88.888 9 sigmod 1 024 0.031 25 77.777 8
从表1可以看出,通过网格法参数寻优后,核函数为RBF的预测准确率最高为88.888 9%;其次是以多项式函数和sigmod函数为核函数的模型,预测准确率为77.777 8%;线性函数为核函数的预测情况较差。因此选用RBF为核函数的SVM模型进行A类(富强粉、精制雪花粉)与B类(麦芯粉、面包粉)的识别。

图 4 第一级SVM模型分类结果
Fig.4 The fi rst level classifi cation results of SVM model
从图4可以看出,-1点表示A类即富强粉和精制雪花粉,0点表示B类即麦芯粉和面包粉。27 个样本中有2 个麦芯粉和1 个面包粉被错分为A类,分类结果较好。
将识别后的两大类样本分别送入下一级的子分类器中,继续细化分类。一个子分类器鉴别富强粉(5 份)与精制雪花粉(7 份),一个子分类器鉴别麦芯粉(8 份)和面包粉(7 份)。
表2 子分类器参数设置及其分类准确率(富强粉与精制雪花粉)
TTaabbllee 22 PPaarraammeetteerr sseettttiinnggss aanndd ccllaassssiiffi i ccaattiioonn aaccccuurraaccyy ooff ssuubb--ccllaassssiiffi i eerrss ffoorr ssttrroonngg ffl l oouurr aanndd rreeffi i nneedd ssnnoowwffl l aakkee ffl l oouurr

核函数 参数 预测准确率/%惩罚参数 Gamma参数线性 1 024 无 66.666 7多项式 8 8 100 RBF 32 1 100 sigmod 32 2 100
由表2可知,除以线性函数为核函数的模型分类结果较差以外,多项式、RBF、sigmod为核函数的SVM模型分类准确率均达到100%,分类情况非常好,实验选取RBF为核函数建立子SVM模型鉴别富强粉与精制雪花粉样本。
表3 子分类器参数设置及其分类准确率(麦芯粉与面包粉)TTaabbllee 33 PPaarraammeetteerr sseettttiinnggss aanndd ccllaassssiiffi i ccaattiioonn aaccccuurraaccyy ooff ssuubb--
ccllaassssiiffi i eerrss ffoorr wwhheeaatt ccoorree ffl l oouurr aanndd bbrreeaadd ffl l oouurr
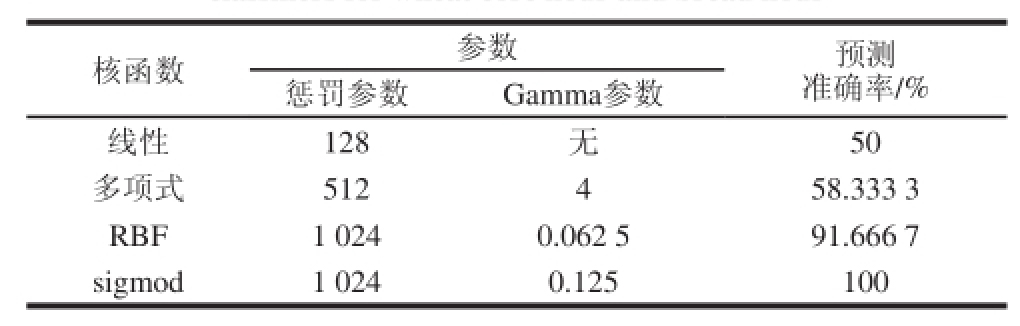
核函数 参数 预测准确率/%惩罚参数 Gamma参数线性 128 无 50多项式 512 4 58.333 3 RBF 1 024 0.062 5 91.666 7 sigmod 1 024 0.125 100
由表3可知,以sigmod为核函数的模型分类结果最好,预测准确率达到100%。RBF函数为核函数的SVM模型分类结果次之,线性核函数分类结果较差。因此,实验选取sigmod为核函数建立子SVM模型鉴别麦芯粉与面包粉样本。
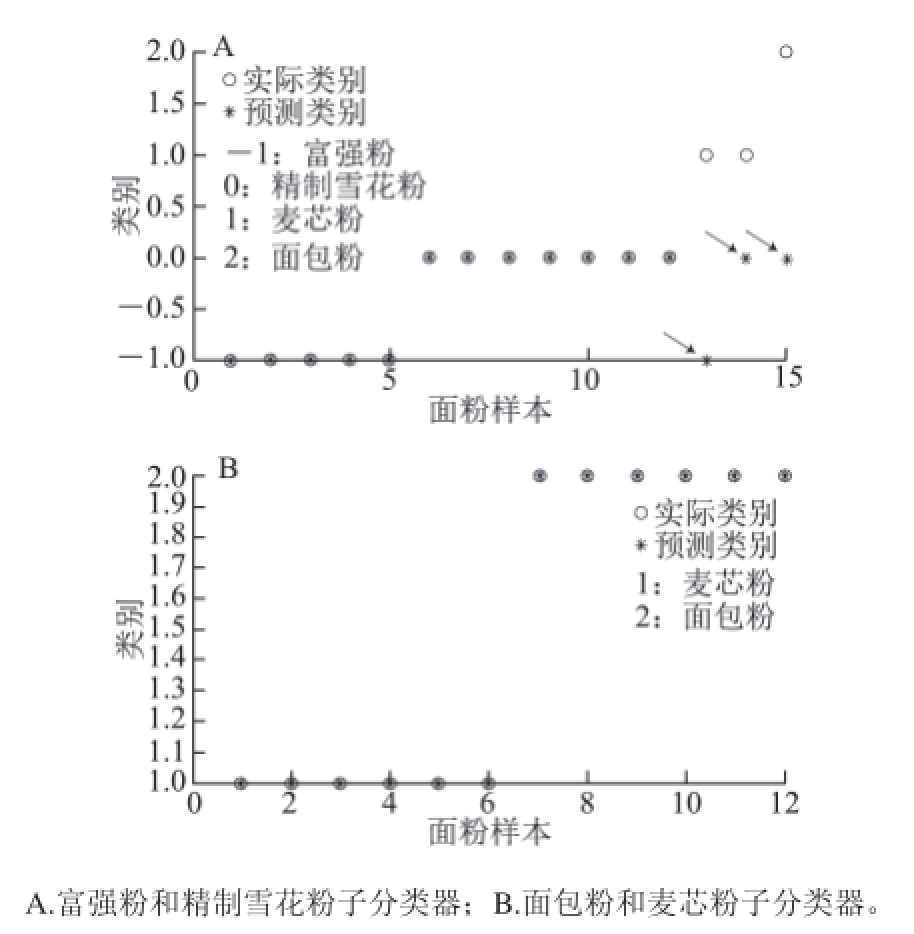
图 5 子分类器分类结果
Fig.5 The classifi cation results of sub classifi er
图5表示第二级两个子分类器的分类结果,-1点表示富强粉,0点表示精制雪花粉,1点表示麦芯粉,2点表示面包粉。可以看出除第一级错分到子分类器图5A中的2 个麦芯粉和1 个面包粉没有正确分类以外,其余样本都被准确识别出来。
研究针对不法商贩将面粉以次充好的社会问题,提出基于中红外光谱结合SVM法对面粉样本种类进行快速的鉴别,以保障消费者的利益不被侵犯。在经过光谱预处理以及马氏距离剔除异常样本的建模前处理,以及通过网格法参数优化和SVM模型核函数预测结果的对比情况下,找出最适合面粉类别分类鉴别的模型以及相关参数。富强粉、精制雪花粉、麦芯粉及面包粉的识别准确率分别为100%、100%、75%和85.71%,模型平均识别准确率达到90.177 5%,为面粉种类鉴别研究提供了具有可行性的数据支持。由于面粉样本的限制,实验仅分类4 种常见面粉,还需收集更多不同种类、不同生产厂家的面粉样本,研究更多种类的鉴别,以及更多分类方法的比较以提高预测准确率。并且将模型不断优化之后,可以将其嵌入到便携式红外光谱仪上以便质检人员现场抽检与鉴别。
参考文献:
[1] 褚小立. 化学计量学方法与分子光谱分析技术[M]. 北京: 化学工业出版社, 2011: 220-241.
[2] 徐继刚, 冯新泸, 管亮, 等. 中红外光谱在润滑油分类识别中的应用[J]. 后勤工程学院学报, 2011, 27(5): 51-55.
[3] 钱贵明, 刘嘉, 张引, 等. 傅立叶变换中红外光谱在食品快速分析与检测中应用[J]. 粮食与油脂, 2013, 26(6): 29-33.
[4] KAROUI R, MAZEROLLES G, BOSSET J O, et al. Utilisation of mid-infrared spectroscopy for determination of the geographic origin of Gruyère PDO and L'Etivaz PDO Swiss cheeses[J]. Food Chemistry,2007, 105(2): 847-854.
[5] GURDENIZ G, OZEN B, FIGEN T. Comparison of fatty acid profi les and mid-infrared spectral data for classifi cation of olive oils[J]. Europe Journal of Lipid Science and Technology, 2010, 112(2): 218-226.
[6] GURDENIZ G, OZEN B. Detection of adulteration of extra-virgin olive oil by chemometric analysis of mid-infrared spectral data[J]. Food Chemistry, 2009, 116(2): 519-525.
[7] 黄红英, 尹齐和. 傅里叶变换衰减全反射红外光谱法(ATR-FTIR)的原理与应用进展[J]. 中山大学研究生学刊: 自然科学, 医学版, 2011,32(1): 20-20.
[8] 张小俊, 姚杰. 红外衰减全反射法(ATR)在橡胶产品分析中的应用[J].高分子材料科学与工程, 2013, 29(7): 127-130.
[9] 徐琳. 傅里叶变换衰减全反射红外光谱法鉴定皮革产品[J]. 光谱实验室, 2006, 22(6): 1274-1276.
[10] 王家俊, 汪帆, 马玲. ATR-FTIR光谱法快速测定BOPP薄膜的厚度和定量[J]. 光谱实验室, 2006, 22(5): 999-1002.
[11] 谢娟英, 张兵权, 汪万紫. 基于双支持向量机的偏二叉树多类分类算法[J]. 南京大学学报: 自然科学版, 2011, 47(4): 354-363.
[12] 丁世飞, 齐丙娟, 谭红艳. 支持向量机理论与算法研究综述[J]. 电子科技大学学报, 2011, 40(1): 2-10.
[13] 王国胜. 支持向量机的理论与算法研究[D]. 北京: 北京邮电大学, 2007.
[14] 宋召青, 崔和, 胡云安. 支持向量机理论的研究与进展[J]. 海军航空工程学院学报, 2008, 23(2): 143-148.
[15] OOMMEN T, MISRA D, TWARAKAVI N K C, et al. An objective analysis of support vector machine based classification for remote sensing[J]. Mathematical Geosciences, 2008, 40(4): 409-424.
[16] BRERETON R G, LLOYD G R. Support vector machines for classifi cation and regression[J]. Analyst, 2010, 135(2): 230-267.
[17] 林颢, 赵杰文, 陈全胜, 等. 近红外光谱结合一类支持向量机算法检测鸡蛋的新鲜度[J]. 光谱学与光谱分析, 2010, 30(4): 929-932.
[18] 谈爱玲, 毕卫红. 基于KPCA和LSSVM的蜂蜜近红外光谱鉴别分析[J]. 激光与红外, 2012, 41(12): 1331-1336.
[19] 张建华, 孔繁涛, 李哲敏, 等. 基于最优二叉树支持向量机的蜜柚叶部病害识别[J]. 农业工程学报, 2014, 30(19): 222-231.
[20] 刘强, 罗长兵, 陈绍江, 等. 近红外光谱分析青贮玉米NDF中判别异常光谱的研究[J]. 光谱学与光谱分析, 2007, 27(8): 1514-1518.
[21] 薛宁静. 多类支持向量机分类器对比研究[J]. 计算机工程与设计,2011, 32(5): 1792-1795.
[22] 孔波, 郑喜英. 支持向量机多类分类方法研究[J]. 河南教育学院学报: 自然科学版, 2010, 19(2): 9-12.
[23] 郎宇宁, 蔺娟如. 基于支持向量机的多分类方法研究[J]. 中国西部科技, 2010, 9(17): 28-29.
[24] 吴静珠, 李慧, 王克栋, 等. 光谱预处理在农产品近红外模型优化中的应用研究[J]. 农机化研究, 2011, 33(3): 178-181.
[25] 褚小立, 袁洪福, 陆婉珍. 近红外分析中光谱预处理及波长选择方法进展与应用[J]. 化学进展, 2004, 16(4): 528-542.
Fast Identifi cation of Flours by Attenuated Total Refl ectance-Fourier Transform Infrared Spectroscopy (ATR-FTIR)Based on Support Vector Machine (SVM)
DOU Ying, SUN Xiaorong*, LIU Cuiling, WEI Lina, HU Yujun
(School of Computer and Information Engineering, Beijing Technology and Business University, Beijing 100048, China)
Key words:fl our; ATR-FTIR; Mahalanobis distance; support vector machine
中图分类号:TS207.3
文献标志码:A
文章编号:1002-6630(2015)24-0224-05
doi:10.7506/spkx1002-6630-201524042
收稿日期:2015-01-21
基金项目:北京市教委科研计划重点项目(KZ201310011012);北京市教委科技创新平台建设项目(PXM_2012_014213_000023);北京市自然科学基金项目(4142012);北京市优秀人才资助项目(2012D005003000007)
作者简介:窦颖(1990—),女,硕士研究生,研究方向为控制理论与控制工程。E-mail:m13146816314_1@163.com
*通信作者:孙晓荣(1976—),女,副教授,博士研究生,研究方向为智能测量技术与数据处理、系统建模与仿真方法、智能控制方法。E-mail:sxrchy@sohu.com